
语料库与词典编纂对词汇教学的启示:
1.词汇的广度与深度知识,词汇的搭配,类联结,语义韵以及同义词和反义词都是词汇教学的重要部分。
2.词汇教学需要核心词汇(高频词)优先。
3.词汇教学需要重视词块教学,语用教学。

语料库与词典编纂对词汇教学的启示:
1.词汇的广度与深度知识,词汇的搭配,类联结,语义韵以及同义词和反义词都是词汇教学的重要部分。
2.词汇教学需要核心词汇(高频词)优先。
3.词汇教学需要重视词块教学,语用教学。
建设小型语料库(任务7-9)
创建小型语料库的意义

一、教学语料库设计原则
1.三大原则:
教学针对性原则;实用性原则;
开放性、资源共享原则




2.三大要点:
需要搜集的语料类型和文件
语料来源及获取语料的方法
入库文本的基本格式及编码



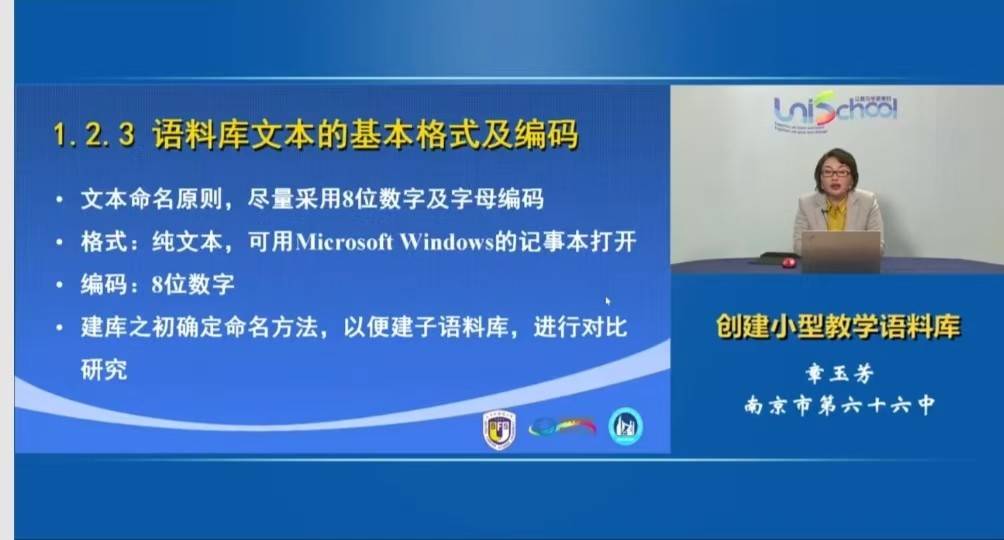
3.语料库命名例子



二、文本信息录入及文本赋码
文本信息
1.文本信息开头

书面语语料库头文件

2.生文本

赋码文本

生文本及赋码文本比较

3.文本录入中的小问题

三、语料库创建所需软件介绍

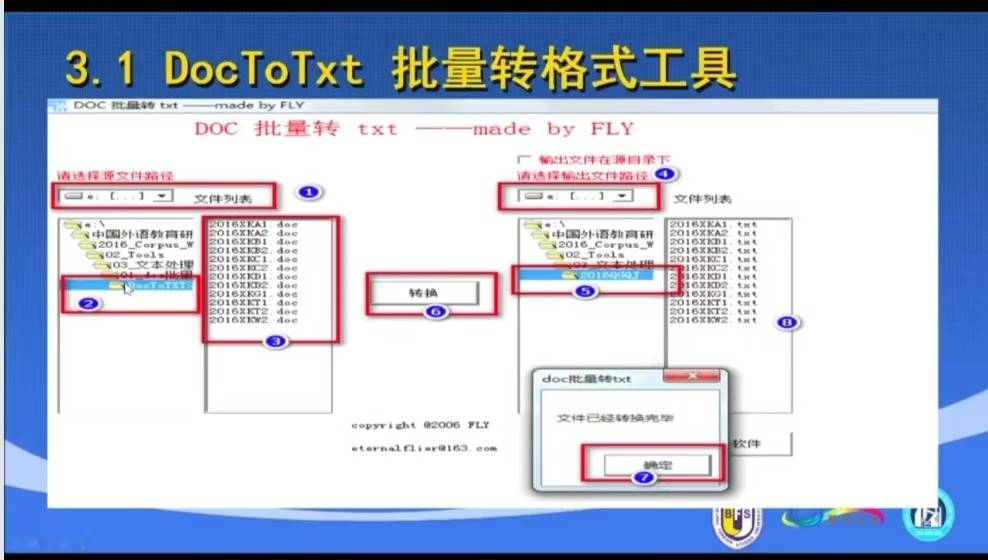
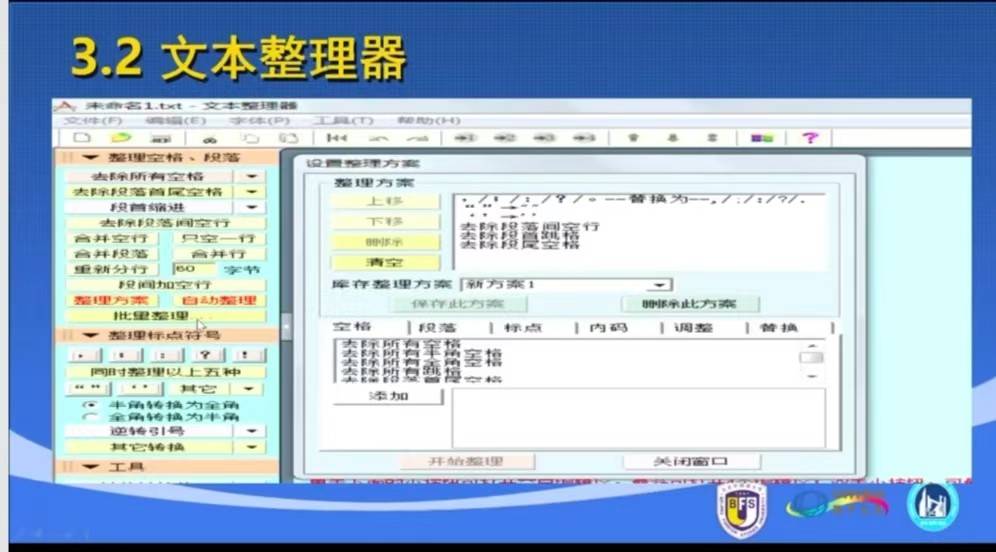


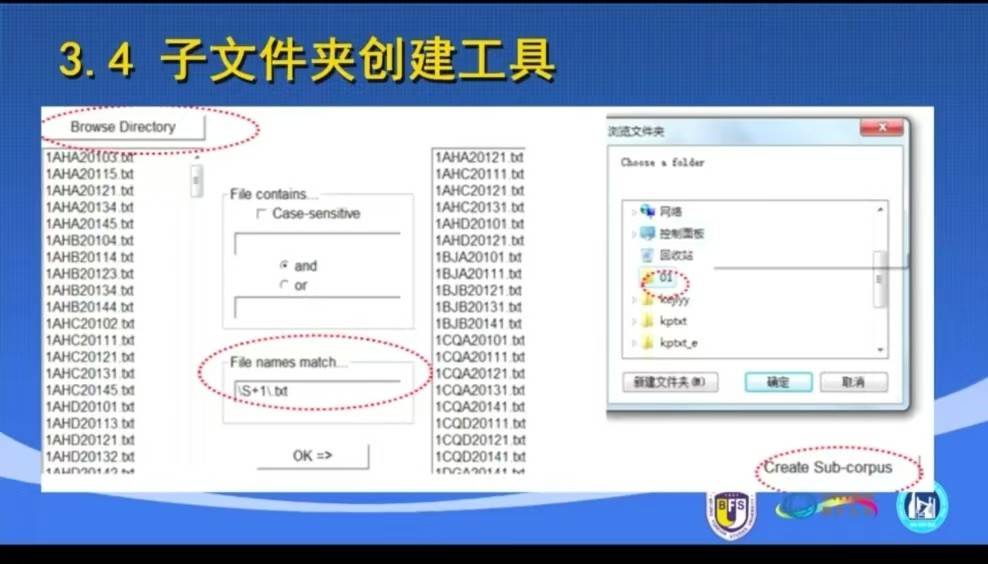
创建小型语料库
(三)文本信息录入、文本赋码
1.文本信息
(1)文头信息——言语言信息
(2)生文本——raw
(3)赋码文本——Tree-Tagger
注意比较生文本和赋码文本
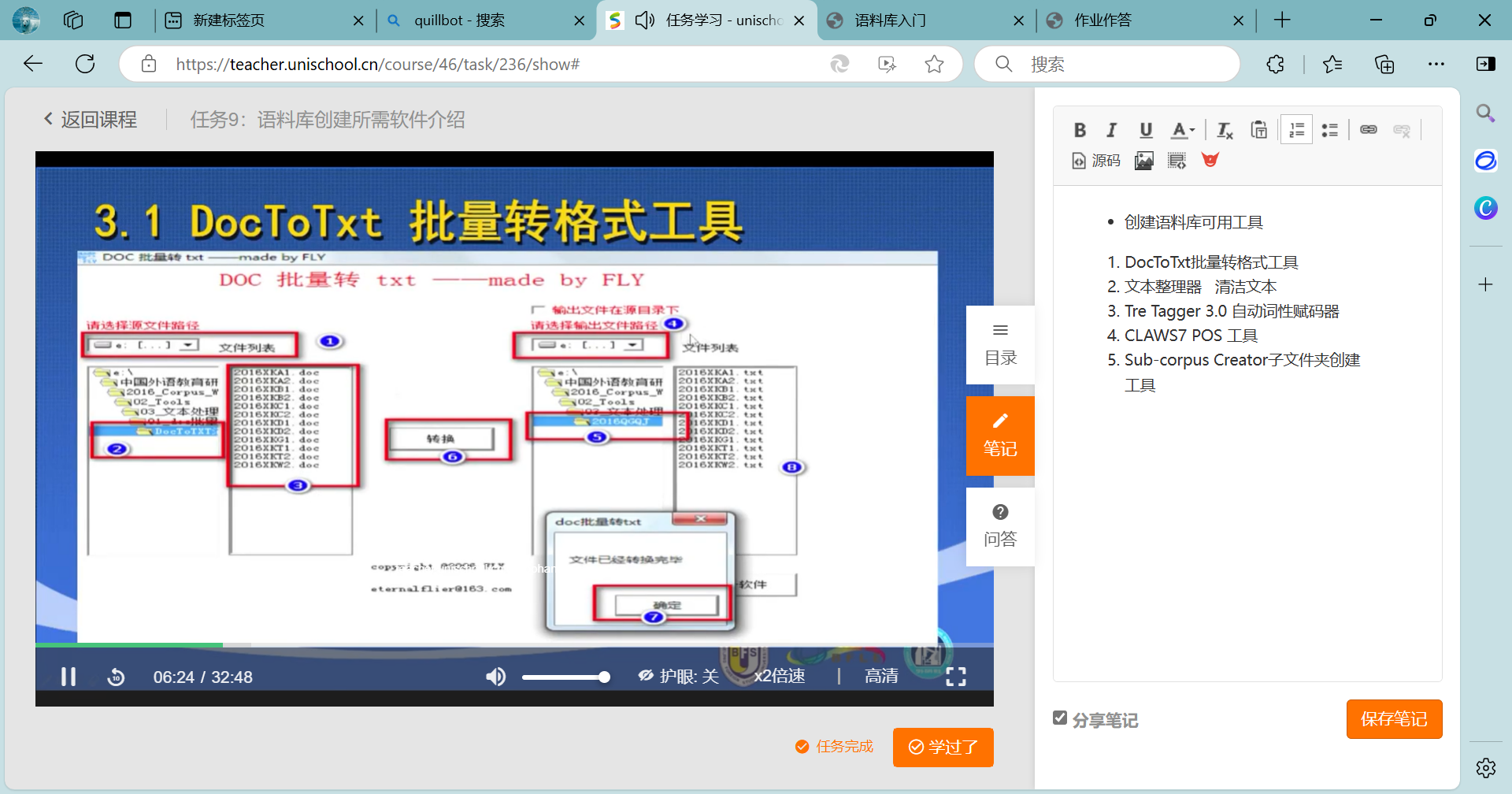

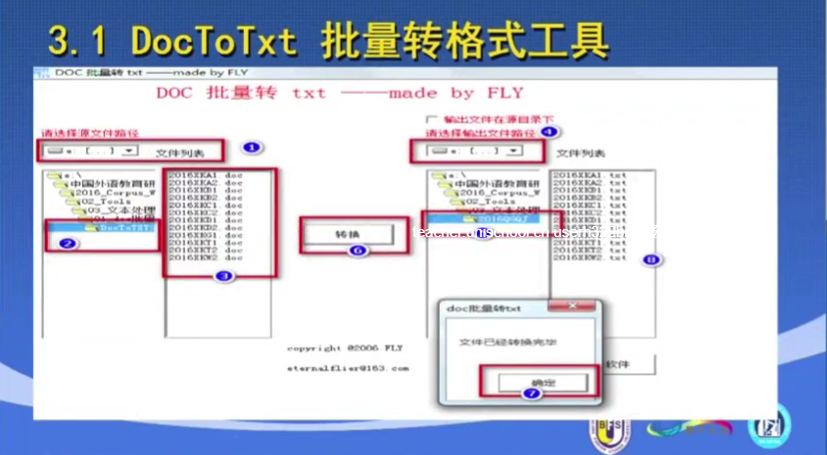
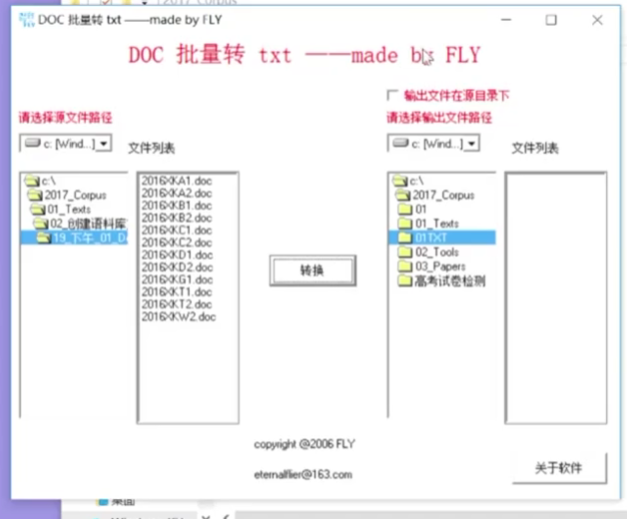
第一步:将文件转为txt格式。
第二步: 处理空格和全角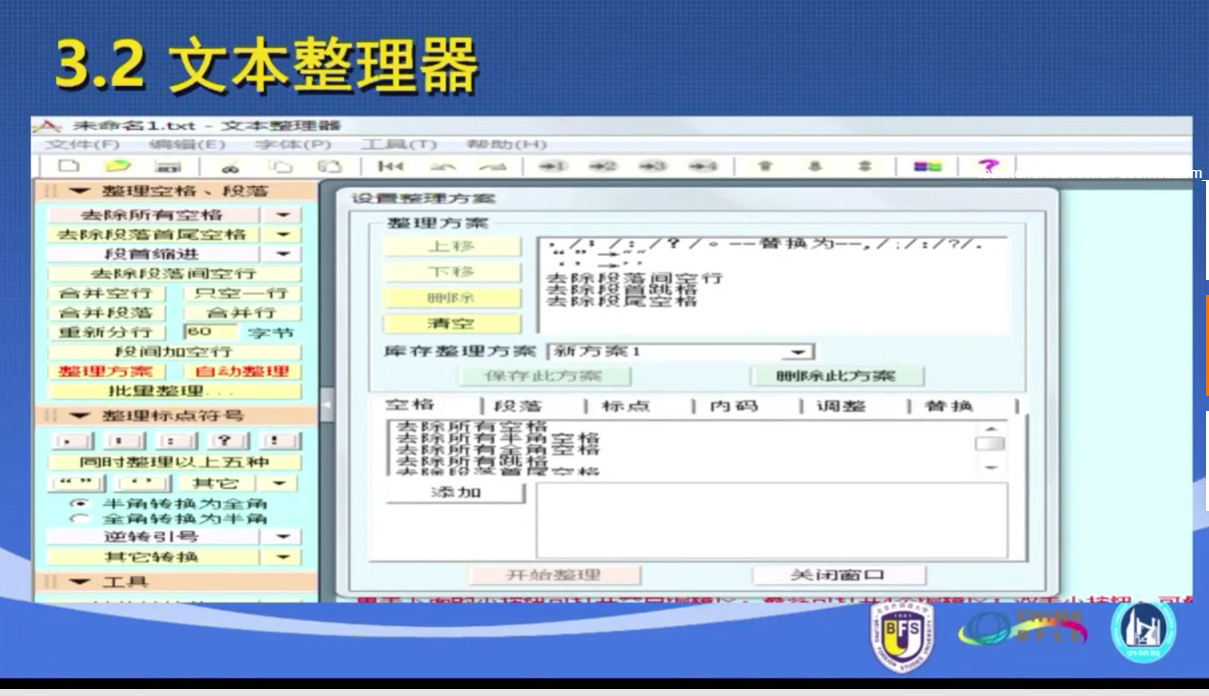 批量处理是,点击“批量处理”
批量处理是,点击“批量处理”
添加整理方案
———————————————————
tree-tagger赋码
“open-dir”打开文件夹

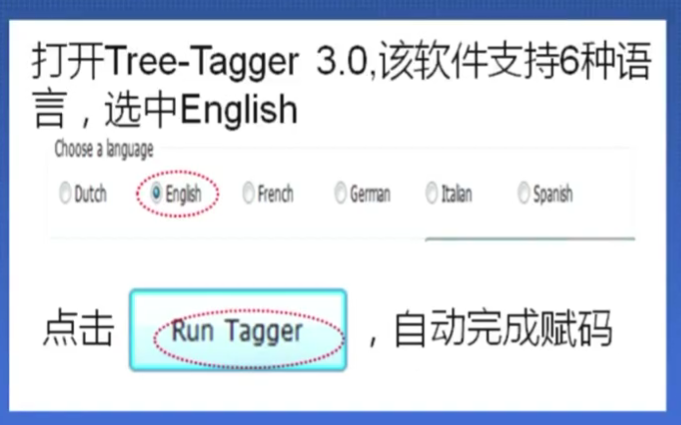 可以备份。
可以备份。
———————————————————
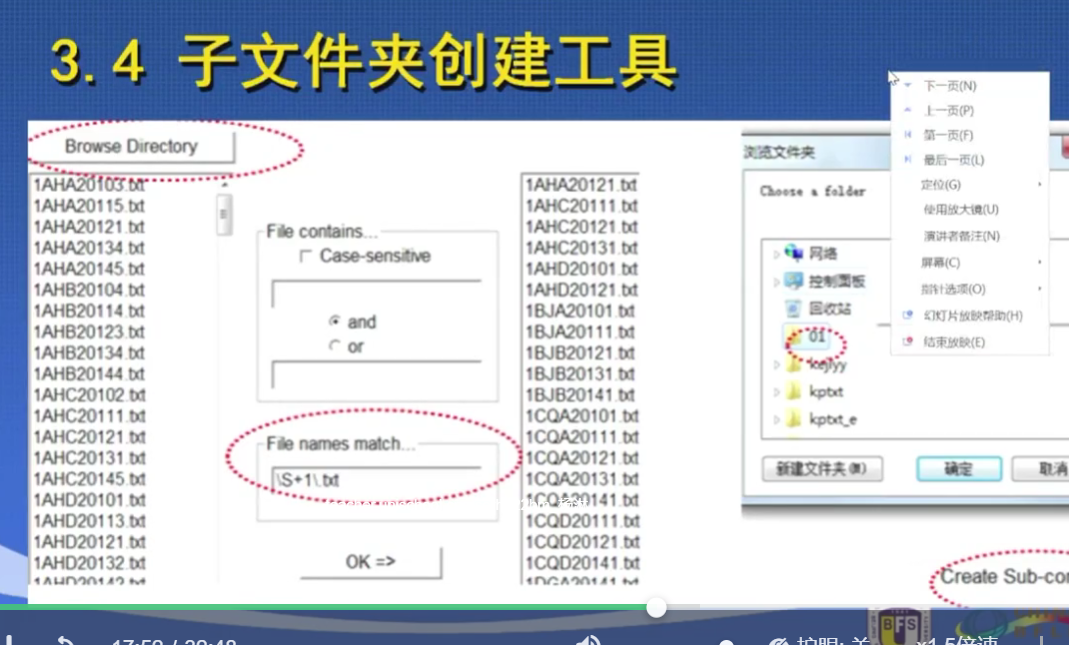 基于所有都是txt文本,可以尝试一下检索式
基于所有都是txt文本,可以尝试一下检索式
 表示非空格
表示非空格
注意提前创建存储的文件夹
例如:
表示检索所有福建卷的内容
其二, 针对不同档

可以表达为
又例如,
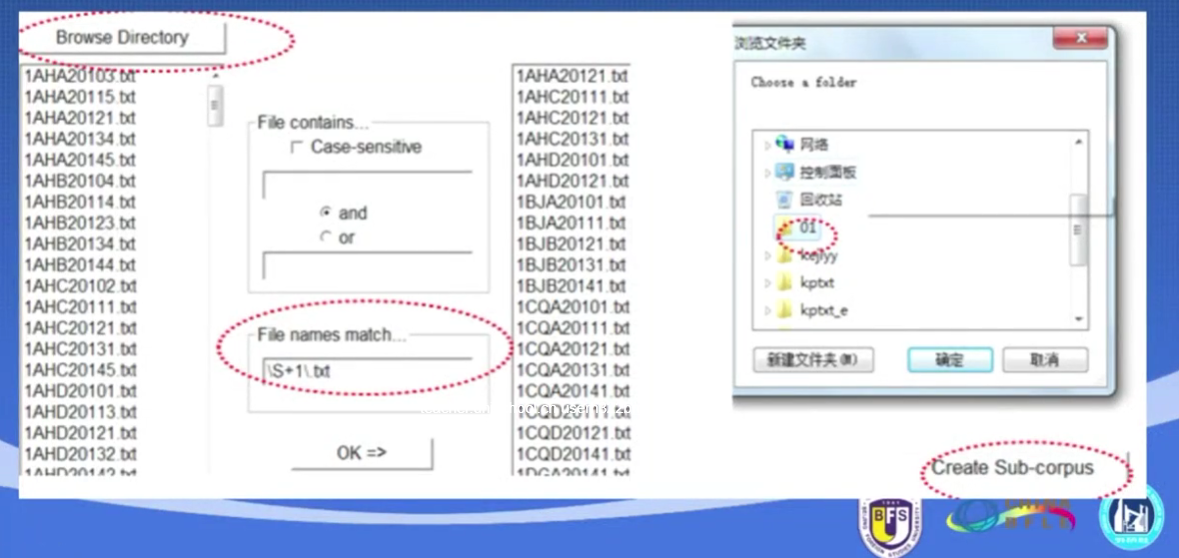
表示以1结尾的非空格文本。
注意:
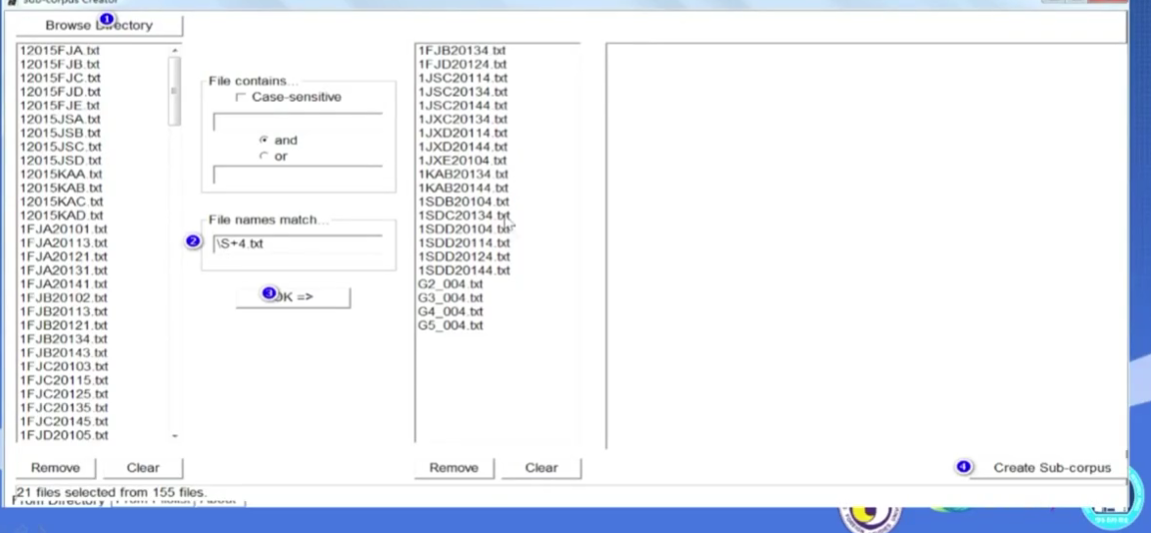
界定要清楚
检索非空格,要
————————
检索文头文件
如 检索18分的
检索18分的
 检索出含有sport的文本
检索出含有sport的文本

 文本信息不能有空格
文本信息不能有空格
 1. 不能使用字典
1. 不能使用字典
ID:建议使用身份证号,也可叫上地区。注意标明规则。
 注意:建立原则,根据目的判断是否要保留语言错误。如果在后期需要提取也可以考虑是否要修改。
注意:建立原则,根据目的判断是否要保留语言错误。如果在后期需要提取也可以考虑是否要修改。 黄色部分为赋码信息。50多种赋码
黄色部分为赋码信息。50多种赋码
 两款软件的准确率无法做到百分百,在研究中要注意考虑。claws7 为付费软件。70多种
两款软件的准确率无法做到百分百,在研究中要注意考虑。claws7 为付费软件。70多种
 此处为简写版,将所有信息尖括号。
此处为简写版,将所有信息尖括号。
timed,限时作文。 注意输入格式。
注意输入格式。

 1. 课程标准的语言知识;内容检索和重组——用教材教
1. 课程标准的语言知识;内容检索和重组——用教材教
3. 中小学的缺少的部分——多模态,吸收到最多百分之五十左右。
4. 历时跟踪;常见错误分析


 通用型和专业型——教学语料库/专业型
通用型和专业型——教学语料库/专业型
常见话题
2. 如果是全国卷,因其文本词数通常是240左右——根据地区的考试实情判断
 语料库的纯洁性——文本真实性的甄别
语料库的纯洁性——文本真实性的甄别


 比如第一位数字所代表的版本信息,初中版本超过十,会占到两位,节约目的,采用二十六字母。
比如第一位数字所代表的版本信息,初中版本超过十,会占到两位,节约目的,采用二十六字母。 注意标注命名原则,以统一标准
注意标注命名原则,以统一标准
文本问头信息<GENDAR>F</GENDER>
Raw Text:
赋码文本:
tree tagger:NN名词单数 NNS名词复数
Claws 7 :NN1 NN2
教材语料库:资源重组
试题语料库:分析命题语料库,某一类型题型学生的失分点
音频及视频语料库:视听结合吸收更多的接收信息
学生口笔语语料库:语言能力的实时跟踪
DocToTxt批量转换格式工具
文本清洁器:批量修改
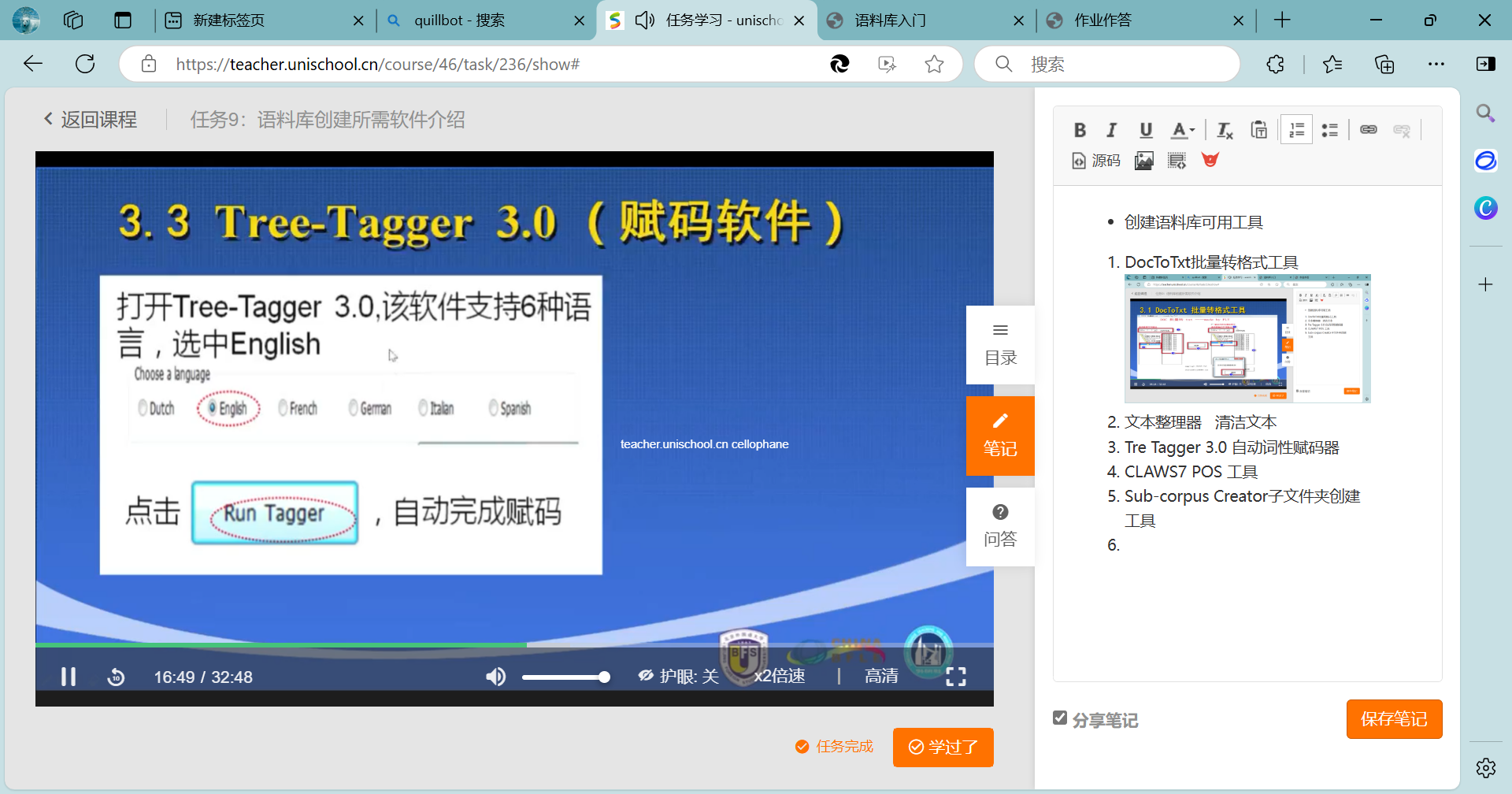
Tree Tagger 自动词形赋码器
文本信息录入及文本赋码:
1.文本文头信息
2.书面语语料库文头文件
3.Raw Test
4.赋码文本(Tree-Tagger 3.0)
5.生文本及赋码文本比较
6.带文头信息文本 (with metadata)
7.文本录入中的小问题
a.撇号不对
b.标点符号后面的单词与标点符号之间无空格
一、创建小型教学语料库:
1.教学语料库设计的原则
a.教学针对性原则
b.实用性原则
c.开放性、资源共享原则
2.文本信息录入及文本赋码
3.语料库创建所需软件介绍
二、语料库设计的特点:
1.需要搜集的语料类型和文类
2.语料来源及获取语料的方法
3.入库文本的基本格式及编码
第二部分: N-gram list作用
1. 相关功能:
N-gram list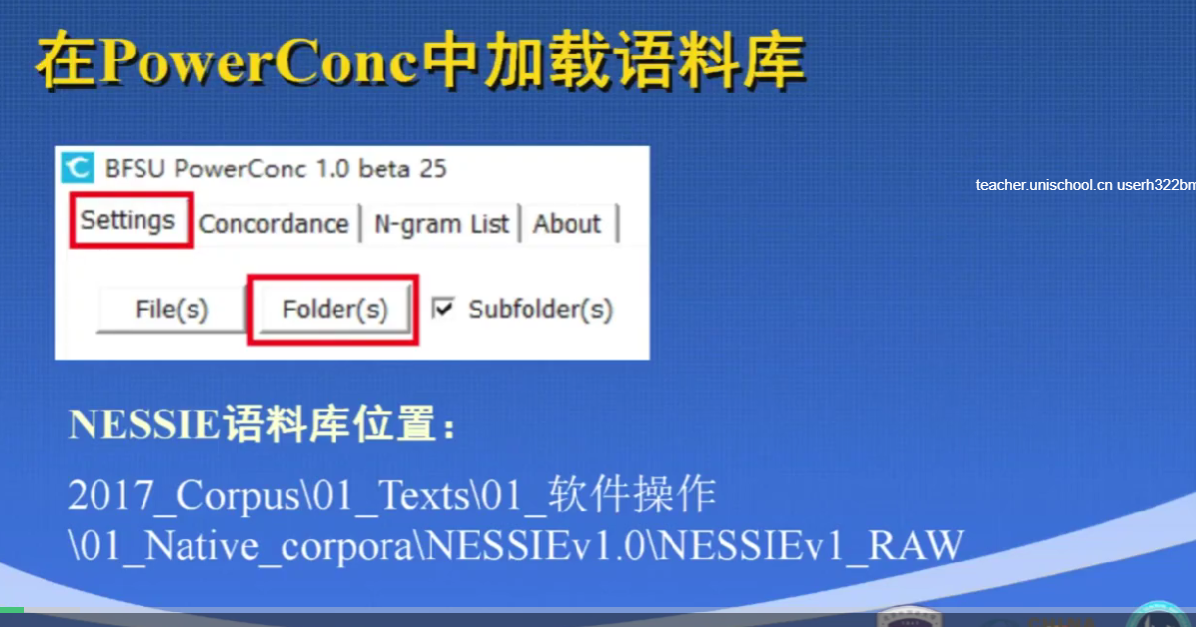
选中源文件后,点击任务栏上方的N-gram,对word 或其他的长度尽心那个搜索,点击count得出频率
每个词典123级表示不一样含义
1、N-gram list 词表
Keyword list 主题词表
2、Tokens:语料库的大小
@look 匹配所有曲折变化形式
sort:排序 sort mode:排序模式
Coll:计算搭配词
Coll Span:搭配跨距
Log-Likelihood:数值越大,搭配强度越大。
检索相关功能
1.Concordance 词汇索引
2.Collocation & Colligation 搭配/类联接
#放在词性类别码之前,匹配该词性大类对应的各词性码子类。
Batch Search 批量检索
2.1.1 常见学习者词典
Oxford Longman Collins
Cambridge Macmillan
2.1.3 学习型词典特点:收词广泛 与时俱进
2.1.4 语料库与词典
语料库为选词立目提供客观依据
语料库提高词典释义的完美性和准确度
语料库为词典提供真实而具有代表性的例证
语料库为词典更新与修订提供保障
2.2 语料库与教材编写
语料库:教材的语料源泉
语料库:检验教材的手段
语料库:基于词频的教材词汇广度分析
2.3 语料库与大纲制定
Willis(1990)
2.4 词汇大纲与教材编写
尽可能的提高核心词汇覆盖率
严格控制课文长度和生词数量
对提高生词复现率的重视
对常用词语搭配的选择的zhong shi
1.1 定义
A collection of texts stored in an electronic database.
1.2 类型 5种
通用/专用语料库
笔语/口语语料库
公时/历时语料库
本族语者/学习者语料库(机读学习者语料库)
“中国英语学习者口笔语语料库”
单语/双语/多语yu liao ku
